Media Summary: [CVPR 2024] PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 Arxiv: Authors: Jihyun ... EpiDiff only takes 12 seconds to generate 16 multiview-consistent and high-quality images. Instead of limited to fixed views, ...
Cvpr 2024 Diffusion 3d Features - Detailed Analysis & Overview
[CVPR 2024] PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 Arxiv: Authors: Jihyun ... EpiDiff only takes 12 seconds to generate 16 multiview-consistent and high-quality images. Instead of limited to fixed views, ... [CVPR 2024] TAMM: TriAdapter Multi-Modal Learning for 3D Shape Understanding In this work, we introduce PartGen, a novel method for compositional/part-level CVPR 2024 paper ProMark:Proactive Diffusion Watermarking for Causal Attribution
project page: 0:00 Introduction 0:47 Method overview 1:23 ... Paper: ID-Blau: Image Deblurring by Implicit Paper: arxiv.org/abs/2312.04410 Code: github.com/SHI-Labs/Smooth-
![[CVPR 2024] Diffusion 3D Features: Decorating Untextured Shapes with Distilled Semantic Features](https://i.ytimg.com/vi/zEwmGMRw7jo/mqdefault.jpg)
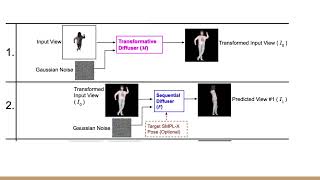
![[CVPR 2024] DiffusionGAN3D](https://i.ytimg.com/vi/gzeWnhMN4EU/mqdefault.jpg)
![[CVPR 2024] DiffMorpher: Unleashing the Capability of Diffusion Models for Image Morphing](https://i.ytimg.com/vi/hv_JgrBIK68/mqdefault.jpg)
![[CVPR 2024] PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion](https://i.ytimg.com/vi/UCLxo8nVmpk/mqdefault.jpg)
![[CVPR 2024] Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation](https://i.ytimg.com/vi/n2ejoig2Zxo/mqdefault.jpg)
![[CVPR 2024] EpiDiff: Enhancing Multi-View Synthesis via Localized Epipolar-Constrained Diffusion](https://i.ytimg.com/vi/pEuwbnnMpL8/mqdefault.jpg)
![[CVPR 2024] TAMM: TriAdapter Multi-Modal Learning for 3D Shape Understanding](https://i.ytimg.com/vi/tK-NPXDr868/mqdefault.jpg)

![[CVPR 2024] ScoreHMR: Score-Guided Diffusion for 3D Human Recovery](https://i.ytimg.com/vi/fi2iXLLoP5M/mqdefault.jpg)


![[CVPR 2024]: PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image Editor](https://i.ytimg.com/vi/AuqZLZT4CjY/mqdefault.jpg)
![[CVPR 2025] PartGen: Part-level 3D Generation and Reconstruction with Multi-View Diffusion Models](https://i.ytimg.com/vi/lPMDgjaPdFs/mqdefault.jpg)

![[CVPR 2024] TiNO-Edit: Timestep and Noise Optimization for Robust Diffusion-Based Image Editing](https://i.ytimg.com/vi/latSSiMcfds/mqdefault.jpg)
![[CVPR 2024] SiTH: Single-view Textured Human Reconstruction with Image-Conditioned Diffusion](https://i.ytimg.com/vi/gixakzI9UcM/mqdefault.jpg)

![[CVPR 2024] Smooth Diffusion: Crafting Smooth Latent Spaces in Diffusion Models](https://i.ytimg.com/vi/Cr53NZ43nrM/mqdefault.jpg)

