Media Summary: Welcome to another deep dive in the Reading Research Papers series. In this video, we go through the paper “Training ... architecture for text, moving through self-attention, multi-head attention, Vision This ten hour compilation brings together everything that I have taught about Vision
Data Efficient Image Transformers Lecture - Detailed Analysis & Overview
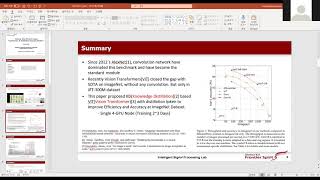
Welcome to another deep dive in the Reading Research Papers series. In this video, we go through the paper “Training ... architecture for text, moving through self-attention, multi-head attention, Vision This ten hour compilation brings together everything that I have taught about Vision MIT 6.7960 Deep Learning, Fall 2024 Instructor: Phillip Isola View the complete course: ... [1] Presenter: Yoonseung Lee [2] Paper: - Training data-efficient image transformers & distillation through attention (https ... 99th, image processing 안종식 Training data-efficient image transformers & distillation through attention paper review post ...
In this video, we cover two ViT variants called DeiT ( An overview of transforms, as used in LLMs, and the attention mechanism within them. Based on the 3blue1brown deep learning ... Papers / Resources ▭▭▭ Colab Notebook: ... 안녕하세요 TensorFlow Korea 논문 읽기 모임 PR-12의 297번째 리뷰입니다 어느덧 PR-12 시즌 3의 끝까지 논문 3편밖에 남지 않았 ...










![[Paper Review] Training data-efficient image transformers & distillation through attention](https://i.ytimg.com/vi/oHnv_S9N1J8/mqdefault.jpg)
![[paper review sub]Training data-efficient image transformers & distillation through attention](https://i.ytimg.com/vi/LYYxv9mv5qw/mqdefault.jpg)







