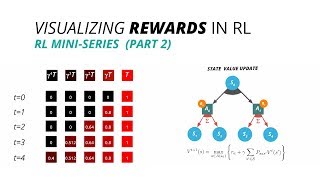
Media Summary: Martin breaks down RLHF's components, including reinforcement learning, state space, action space, Generative Large Language Models, like ChatGPT and DeepSeek, are trained on massive text based datasets, like the entire ... In my 2-Minute Neuroscience videos I explain neuroscience topics in about 2 minutes or less. In this video, I cover the
How Does A Reward Function - Detailed Analysis & Overview
Martin breaks down RLHF's components, including reinforcement learning, state space, action space, Generative Large Language Models, like ChatGPT and DeepSeek, are trained on massive text based datasets, like the entire ... In my 2-Minute Neuroscience videos I explain neuroscience topics in about 2 minutes or less. In this video, I cover the Created by Carole Yue. Watch the next lesson: ... ... 10:20 - Reinforcement Learning with Verifiable Rewards 17:06 - Creating an Environment 21:23 - Creating Full episode with Sergey Levine (Jul 2020): Clips channel (Lex Clips): ...
For more information about Stanford's Artificial Intelligence professional and graduate programs, visit: Andrew ... Direct Preference Optimization (DPO) to finetune LLMs without reinforcement learning. DPO was one of the two Outstanding Main ... Forget manually labeling thousands of tokens. With Reinforcement Fine-Tuning (RFT), you Let's talk about one of the more important concepts in reinforcement learning: q-learning ABOUT ME ⭕ Subscribe: ...