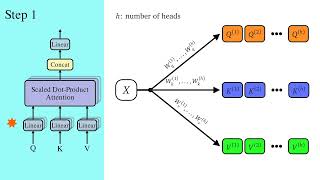
Media Summary: In this video, I'll be deriving and coding Flash ERRATA: - In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should ... Transformers achieve remarkable performance in several tasks but due to their quadratic complexity, with respect to the input's ...
Linear Attention Explained From First - Detailed Analysis & Overview
In this video, I'll be deriving and coding Flash ERRATA: - In slide 23, the indices are incorrect. The index of the key and value should match (j) and theindex of the query should ... Transformers achieve remarkable performance in several tasks but due to their quadratic complexity, with respect to the input's ... Thanks to KiwiCo for sponsoring today's video! Go to and use code WELCHLABS for 50% off ... Build better full-stack authentication and user management with Clerk: -- We just launched the ... An overview of transforms, as used in LLMs, and the






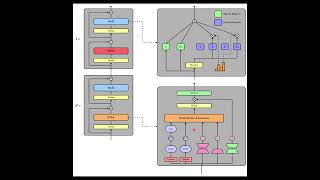
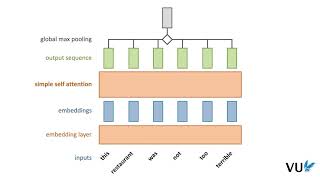


![How DeepSeek Rewrote the Transformer [MLA]](https://i.ytimg.com/vi/0VLAoVGf_74/mqdefault.jpg)