Media Summary: Take your personal data back with Incogni! Use code WELCHLABS at the link below and get 60% off an annual plan: ... A discussion on the philosophy of deep learning, Art by Clipped from episode 19 of AXRP: Transcript of that episode: ...
Mechanistic Interpretability And How Llms - Detailed Analysis & Overview
Take your personal data back with Incogni! Use code WELCHLABS at the link below and get 60% off an annual plan: ... A discussion on the philosophy of deep learning, Art by Clipped from episode 19 of AXRP: Transcript of that episode: ... AI models are trained and not directly programmed, so we don't understand how they do most of the things they do. Our new ... This is a talk I gave to my MATS 9.0 training scholars about the big picture of mech interp - as of Oct 2025, what had changed? How can we reverse engineer what a neural network is doing? In this IASEAI '25 session, An Introduction to
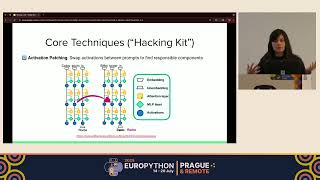
A surprising fact about modern large language models is that nobody really knows how they work internally. At Anthropic, the ... This talk explores the latest research shaping AI Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... ACL SIG-FinTech x TFAI Webinar Series ( Understanding and improving EuroPython 2025 — South Hall 2B on 2025-07-17] *Hacking This has been my favorite video so far to make! I think
Full 1h06 interview on Patreon: Daniel is currently a PhD candidate at UC Berkeley being ... ai In this video, we answer two questions. What is AI Deep neural networks successfully power modern AI, but they operate as black boxes. In traditional software, we can read the ... Modify the behavior or the personality of a model at inference time, without fine-tuning or prompt engineering. Read the blog post ... In this video, we explain what we know (and what we don't know!) about how
![The Dark Matter of AI [Mechanistic Interpretability]](https://i.ytimg.com/vi/UGO_Ehywuxc/mqdefault.jpg)