Media Summary: In this video, we break down NCCL (NVIDIA Collective Communications Library) — the backbone of multi-GPU and multi-node ... 2026 High Performance Computing Lecture 5 Accelerators & Graphical Processing Units Part Two Advanced Scientific ... Anima Anandkumar, UC Irvine Computational Challenges in Machine Learning ...
Nair An Efficient Distributed Deep - Detailed Analysis & Overview
In this video, we break down NCCL (NVIDIA Collective Communications Library) — the backbone of multi-GPU and multi-node ... 2026 High Performance Computing Lecture 5 Accelerators & Graphical Processing Units Part Two Advanced Scientific ... Anima Anandkumar, UC Irvine Computational Challenges in Machine Learning ... OSDI '22 - Alpa: Automating Inter- and Intra-Operator Parallelism for In 2024, LauzHack organized its first bootcamp on Efficient distributed algorithms for Convolutional Neural Networks
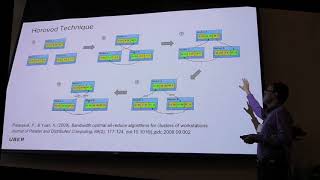
Paper by Moiz Arif, Kevin Assogba, M. Mustafa Rafique and Sudharshan Vazhkudai, presented at ICPP'22. Sowmya Shree Project Engineer CDAC Pune The poster presents an approach to scalable, secure, and As part of the ALCF Hands-on HPC Workshop, the ALCF's Huihuo Zheng provides a talk over In this video from the Stanford HPC Conference, Alex Sergeev from Uber presents: An Uber Journey in Description: This webinar is focused on the Horovod Episode 50 of the Stanford MLSys Seminar Series! Resource-
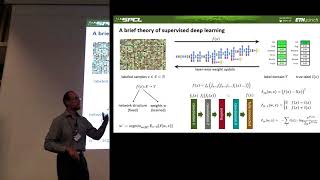
Speaker: Shigang Li Venue: ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 2022) ... In this video from 2018 Swiss HPC Conference, Torsten Hoefler from (ETH) Zürich presents: Demystifying Parallel and