Media Summary: We see how using a parameterized model, we can train the model to learn the value of a given policy. We can use both ... We learn policy networks and their learning objectives. We see how er can formulate their objective to train a computational policy ... We discuss the space size of a realistic environment to see that classical tabular
Uoft Rl Course Lecture 37 - Detailed Analysis & Overview
We see how using a parameterized model, we can train the model to learn the value of a given policy. We can use both ... We learn policy networks and their learning objectives. We see how er can formulate their objective to train a computational policy ... We discuss the space size of a realistic environment to see that classical tabular We see that the best way to present the environment mathematically is to look at it as a state-dependent system. This provides us ... We take a look at the example of Mountain Car to see how using function approximation gives us more flexibility as compared to ... We introduce the notion of reinforcement learning and understand how it differs to classic learning tasks in its nature.
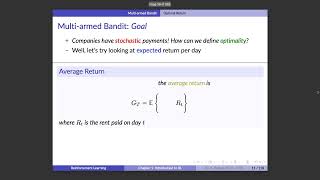
The value function enables us to define the notion of Optimal Policy. This formulates concretely the main objective in We get over the idea of normalization and its impact on training. This motivates us to learn Batch Normalization scheme. We take a look at a very first example, the multi-armed bandit problem, and see how optimally or randomly playing could change ...