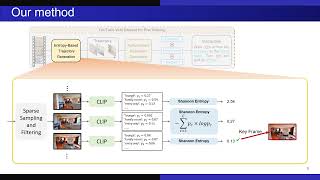
Media Summary: Authors: Fengda Zhu, Yi Zhu, Xiaojun Chang, Xiaodan Liang Description: vision and language navigation in the real world AwareVLN: Reasoning with Self-awareness for Vision-Language Navigation
Vision Language Navigation With Self - Detailed Analysis & Overview
Authors: Fengda Zhu, Yi Zhu, Xiaojun Chang, Xiaodan Liang Description: vision and language navigation in the real world AwareVLN: Reasoning with Self-awareness for Vision-Language Navigation By Qi Wu (The University of Adelaide) and Peter Anderson (Google Research) - VLN Tasks and Datasets 0:00 - Evaluation ... While recent large vision-language models (VLMs) have improved generalization in This video presents SPAN-Nav, an end-to-end foundation model for embodied
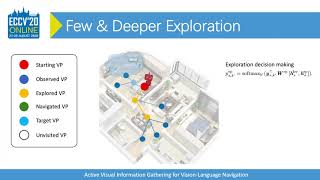
Presentation of our eccv 2020 paper: Active visual information gathering for Liyiming Ke, Xiujun Li, Yonatan Bisk, Ari Holtzman, Zhe Gan, Jingjing Liu, Jianfeng Gao, Yejin Choi and Siddhartha Srinivasa ... Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Authors: Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, Jianfeng Gao Description: Learning to ImagineUAV: Aerial Vision-Language Navigation via World-Action Modeling and Kinodynamic Planning Paper explanation of Soft Expert Reward Learning for
Vision Language Model-based Human-Robot Interactive Navigation and Manipulation



![[CVPR 2021 VQA2VLN Tutorial] Introduction to Vision Language Navigation](https://i.ytimg.com/vi/r1ZeomlYXmo/mqdefault.jpg)