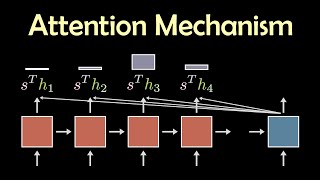
Media Summary: More Recent version for Mamba: A talk for MLSys surveying recent methods ... To try everything Brilliant has to offer—free—for a full 30 days, visit . Transformers are notoriously resource-intensive because their self-
Do We Need Attention Linear - Detailed Analysis & Overview
More Recent version for Mamba: A talk for MLSys surveying recent methods ... To try everything Brilliant has to offer—free—for a full 30 days, visit . Transformers are notoriously resource-intensive because their self- An overview of transforms, as used in LLMs, and the Take the Deep Learning Specialization: Check out all our courses: Subscribe to ... A complete explanation of all the layers of a Transformer Model: Multi-Head Self-
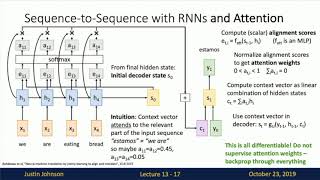
Abstract: The dominant sequence transduction models are based on complex recurrent or ... Check out the latest (and most visual) video on this topic! The Celestial Mechanics of